
One thing that always surprises me when teaching a security class to developers is how little they understand about HTTP. Sure, everyone knows that a HTTP 500 error is a problem on the server, and 404 means the file is missing, but few actually understand how HTTP works at a lower level. This is critical to understanding most web application vulnerabilities and will help you be a much better web developer, so lets dive in!
Skip this if you have a decent understanding of HTTP. Otherwise, it will be a great refresher. First, let’s start with the super-basic before we quickly move into more advanced topics — HTTP. HTTP is the protocol that is used by web servers and browsers to communicate. HTTP is based on a request and a response.

When the you type in a webpage URL in the browser and hit Enter, the browser makes an HTTP GET request. Here is an example of what that looks like:
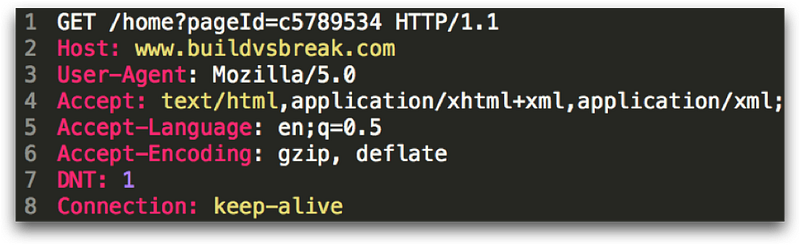
There are a few things worth noting in the screenshot above. Let’s take a look at the first line. First, the HTTP “verb” is GET, which is generally used to retrieve a document, image, or other internet resource. We will look at the other verbs in a minute. Next, the webpage being requested is “/home”. Anything after the “?” are parameters, which come in key/value pairs. Finally, the HTTP version is provided, which in this case is 1.1.
The rest of the lines are HTTP headers, which do things like: tell the webserver what website to retrieve, based on the domain (Host:); report the user-agent and acceptable encoding and language; and other browser-specific options.
From a security perspective, we need to be aware that parameters in the querystring get logged all over the place, so we want to make sure nothing sensitive or important goes there (think passwords, email addresses, or API keys).
Post
Another HTTP request is the POST, which works almost exactly like the GET request except the parameters are sent in the body of the request instead of on the first line. This is good for security since these values are generally not logged by default on webservers, proxies, or other software as the request is transmitted over the internet.
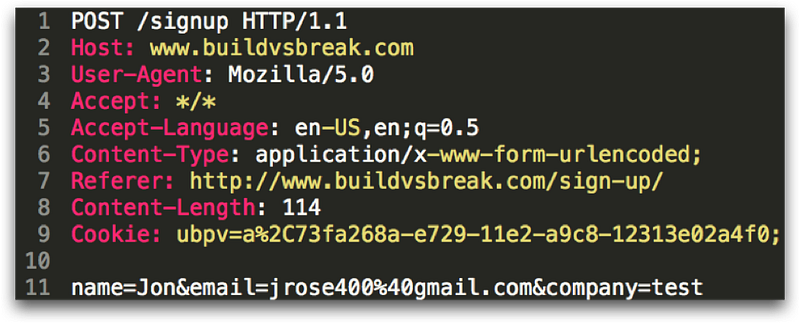
Other request types are OPTIONS, HEAD, PUT, DELETE, and a few other more obscure values, however GET and POST are the most common. Let’s take a look at the HTTP response:
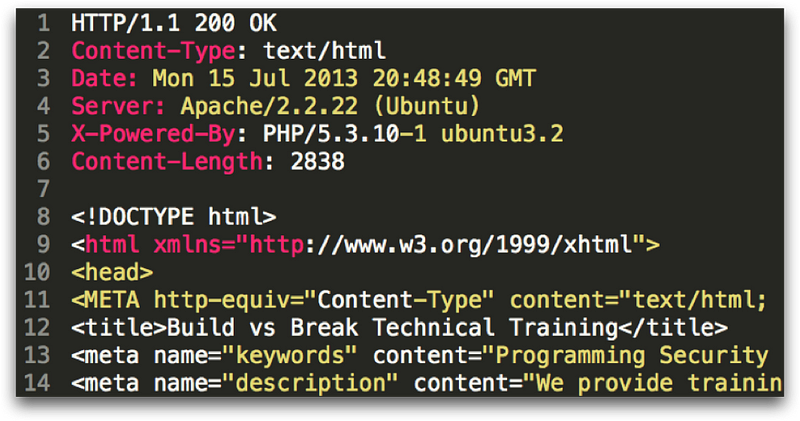
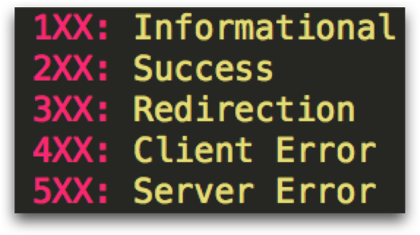
HTTP responses are similar to HTTP requests in that they are text based and contain HTTP headers. On the first line above, the HTTP response returns the HTTP status code. When everything is going right, this will be 200 OK. Below are the list of status codes which can be returned:
After the status code, some server headers are sent, including information about the type of server and software it’s running. Next, the body of the response contains the data we requested, which is generally HTML, CSS, Javascript, or binary data like an image or PDF.
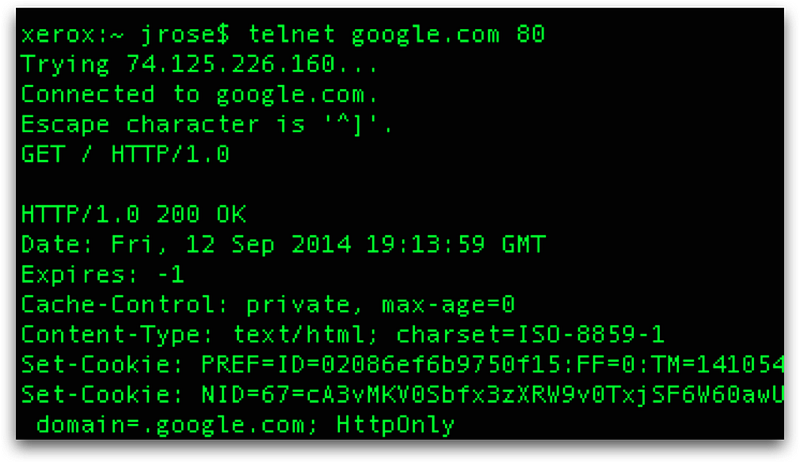
Since HTTP is a text-based protocol, it’s easy to make HTTP requests. You can try this by running telnet and connecting to an HTTP server and then manually making a HTTP GET request. Try it yourself by typing “telnet google.com 80”.
Then, when telnet connects to the webserver, you can manually make an HTTP request by typing:
“GET / HTTP/1.0 (return, return)”
This should return the HTTP response for the homepage.
That’s it, now you know the basics of HTTP. Here are the important parts:
- HTTP is a text based protocol
- It is made up of requests and responses
- Its’ responses have a status code
Now that you have that covered, check out some hacking tools in the blog post Web Hacking Tools: Proxies.